WorldAgen
Unified State-Action Prediction with Test-Time World Model Training
🚀 AAAI 2026
How can vision-language-action (VLA) models adapt to new environments where world dynamics shift? Existing methods that combine world modeling with action prediction rely on pretraining on static datasets and lack mechanisms for active adaptation at deployment time, so they struggle to generalize to unseen object configurations and dynamics.
We present WorldAgen, a unified framework that jointly learns world modeling and action prediction while enabling Test-Time Training (TTT). A shared Transformer backbone hosts two heads: a world model head that predicts future states from past state-action trajectories, and a policy head that predicts actions conditioned on task instructions. A Mixed Unidirectional Attention Mask disentangles the two heads within a single architecture.
At test time, WorldAgen samples exploratory actions, collects ground-truth state transitions, and performs lightweight TTT updates to refine its world model. This online adaptation sharpens the model's understanding of the environment and, in turn, yields more accurate action predictions — delivering consistent gains on CALVIN and LIBERO.
Method
WorldAgen unifies a task-conditioned policy and a task-agnostic world model inside a single Transformer backbone, then adapts the world model online at deployment with Test-Time Training.
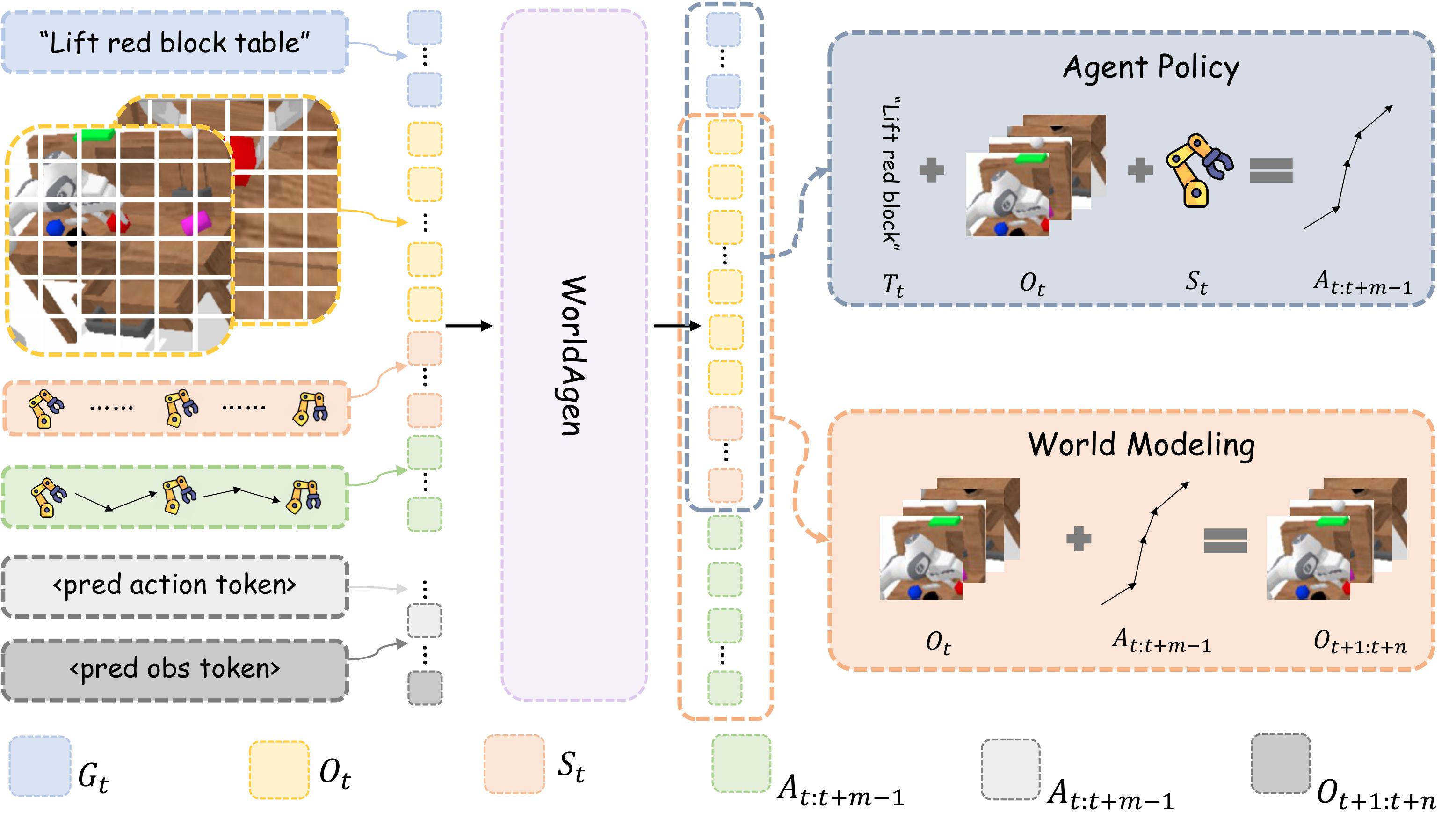
Joint State-Action Modeling
The policy head predicts actions conditioned on the task; the world model head predicts future observations independent of the task. Training them jointly aligns scene understanding with action prediction and produces richer representations of dynamics.
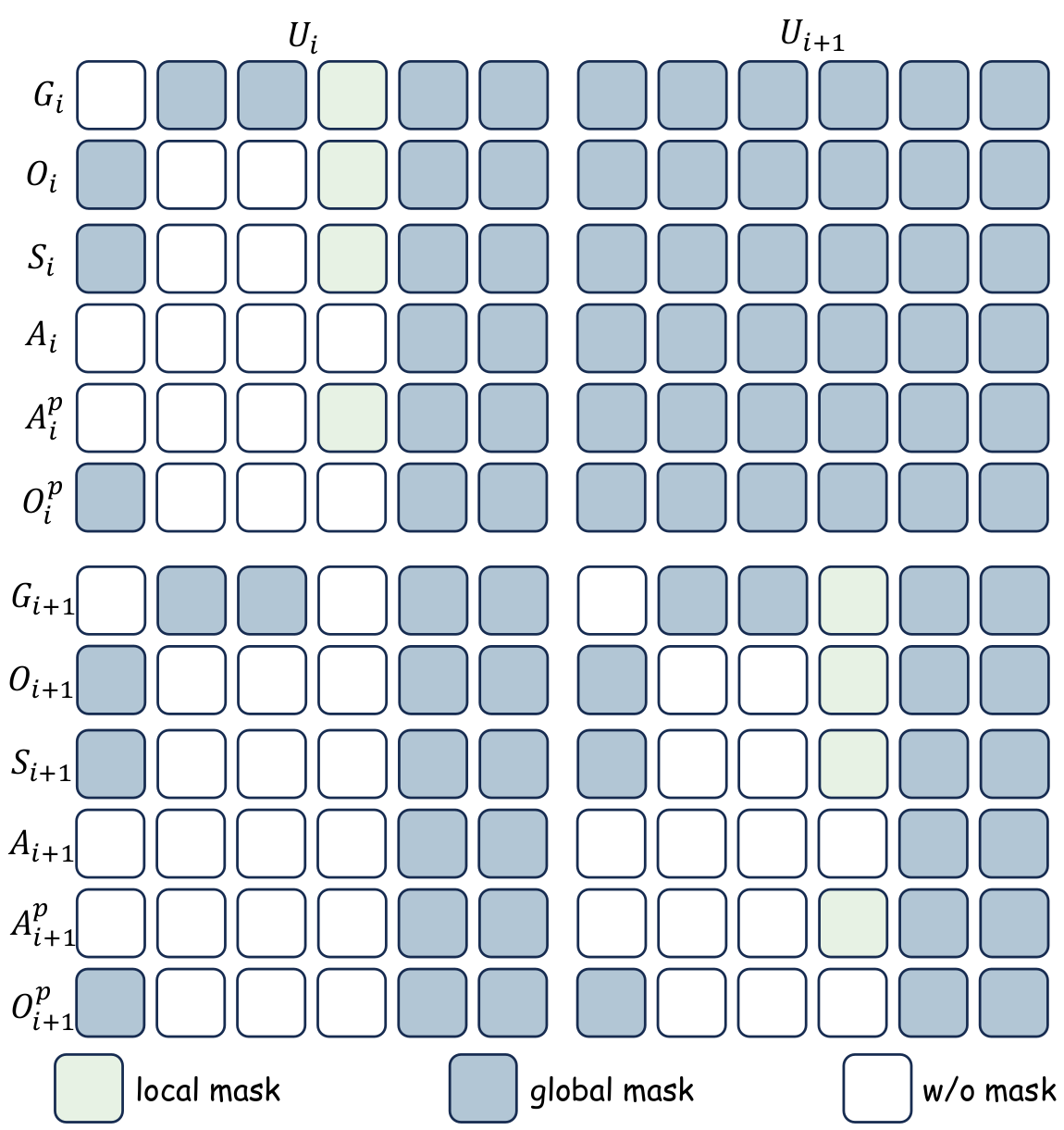
Mixed Unidirectional Attention Mask
A local mask blocks intra-step leakage between the heads, and a global mask keeps the world model invisible to the task instruction. This lets both heads share one backbone while staying strictly causal and decoupled.
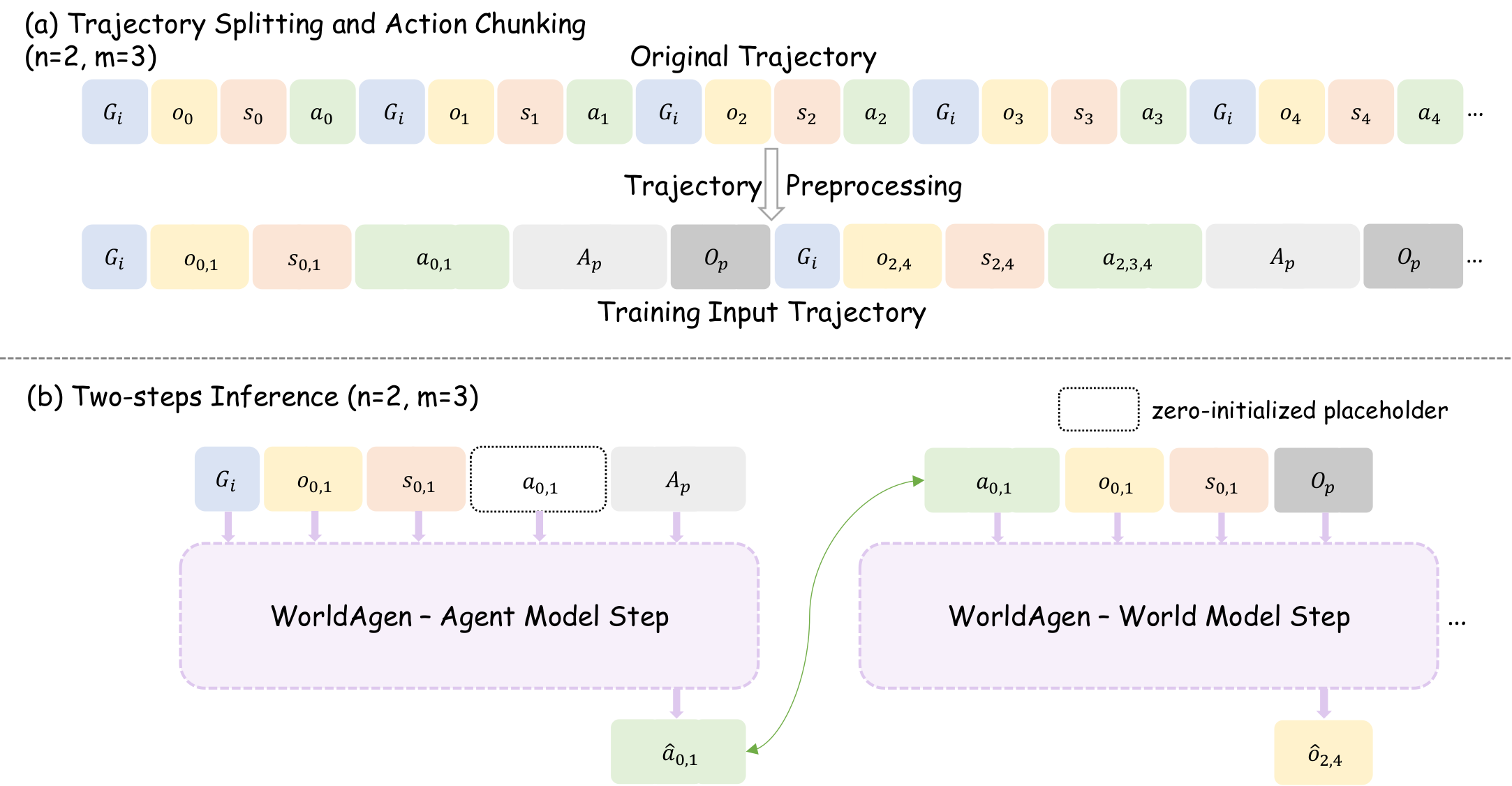
Two-Stage Test-Time Training
Stage 1: free exploratory rollouts collect unlabeled state transitions. Stage 2: a few LoRA updates adapt only the world model on the observation loss — improving environment modeling without touching the policy or needing task labels.
Results
WorldAgen matches or beats state-of-the-art VLA baselines, and Test-Time Training of the world model head delivers further gains on both CALVIN and LIBERO.
CALVIN (Long-Horizon)
Success rate (%) for completing 5 consecutive tasks, and average sequence length (Avg. Len.).
| Method | T1 | T2 | T3 | T4 | T5 | Avg. Len. |
|---|---|---|---|---|---|---|
| RoboFlamingo | 82.4 | 61.9 | 46.6 | 33.1 | 23.5 | 2.47 |
| SuSIE | 87.0 | 69.0 | 49.0 | 38.0 | 26.0 | 2.69 |
| GR-1 | 85.4 | 71.2 | 59.6 | 49.7 | 40.1 | 3.06 |
| 3D Diffusor Actor | 92.2 | 78.7 | 63.9 | 51.2 | 41.2 | 3.27 |
| CLOVER | 96.0 | 83.5 | 70.8 | 57.5 | 45.4 | 3.53 |
| Seer | 93.0 | 82.4 | 72.3 | 62.6 | 53.3 | 3.64 |
| Seer-Large | 92.7 | 84.6 | 76.1 | 68.9 | 60.3 | 3.83 |
| WorldAgen | 96.3 | 87.7 | 76.8 | 67.3 | 59.1 | 3.87 |
| WorldAgen-TTT | 96.6 | 88.5 | 78.5 | 68.7 | 60.5 | 3.93 |
LIBERO-10 (Multi-Task)
Average success rate (%) on the LIBERO-10 long-horizon suite.
| Method | Avg. Success |
|---|---|
| MT-ACT | 41.0 |
| OpenVLA | 54.0 |
| MVP | 68.2 |
| MPI | 77.3 |
| Seer | 78.7 |
| WorldAgen | 75.5 |
| WorldAgen-TTT | 79.0 |
Test-Time Training in Action
Qualitative CALVIN rollouts before and after Test-Time Training. Each pair uses the same task sequence, showing how world model adaptation changes the agent's behavior.
Task: rotate blue block right -> move slider right -> lift red block from slider -> place in slider -> turn off lightbulb


Task: open drawer -> push red block right -> move slider left -> lift pink block from slider -> place in slider


Task: rotate pink block right -> turn off LED -> lift pink block -> place in slider -> open drawer


Cite
If you use WorldAgen or its trained models, please cite our paper.
@article{wan2026worldagen,
title = {WorldAgen: Unified State-Action Prediction with Test-Time World Model Training},
author = {Wan, Chi and Wang, Kangrui and Si, Yuan and Zhang, Pingyue and Li, Manling},
year = {2026}
}